Integrating ArchivesSpace and Archivematica at the Bentley Historical Library
On Wednesday, February 19, 2020, I gave a talk (along with Sarah Romkey, Heather Greer Klein, and Bonnie Gordon) for the Integrations with ArchivesSpace webinar series. This is an adaptation of that talk. You can watch the video (recorded by ArchivesSpace), or just see my slides, if you prefer.

Institutional Context
I thought I’d start with an overview of our institutional context/technical ecosystem. We’ve got a lot going on here! We’ve got:
- ArchivesSpace for administrative and technical metadata;
- Archive-It for web archives;
- Archivematica for born-digital processing and Archival Information Package (AIP) creation;
- DSpace for preservation of and access to born-digital materials;
- Kaltura for access to streaming A/V;
- a homegrown system, the Digital Library eXtension Service (DLXS) for access to finding aids, and preservation of and access to digitized text and image collections; and
- Aeon for request management.
(And I’m not even mentioning all of the other more localized database and spreadsheet systems we use here as well.)
It’s really important to note that these systems are used by a wide variety of stakeholders within the Bentley–including the “back of the house” Curation team and the “front of the house” Reference and Academic Programs team–as well as beyond–including novice researchers like University of Michigan (U-M) undergrads and more advanced researchers from both inside and outside the U-M community, as well as the general public.
They are likewise hosted and supported by a wide variety of stakeholders. For some, we rely on U-M Library Library Information Technology (LIT), for others, we rely on U-M Information Technology Services (ITS), and for still others, we’re experimenting with doing it ourselves.
Managing all of these systems–especially the handoffs of data and metadata between them–can get overwhelming. So we actively look for ways to integrate them with one another, creating a kind of functional coupling between them so that they act as a coordinated whole to fulfill a number of archival workflows. And actually the integration I’ll be talking about today was part of a larger project that’s kind of the one that kicked this whole thing off for us.
That is, the Archivematica-ArchivesSpace integration that I’ll talk about today was actually part of larger, Mellon Foundation-funded ArchivesSpace-Archivematica-DSpace Workflow Integration project (2014-2016) that united three Open-Source Software platforms.
The point of the ArchivesSpace-Archivematica portion of the integration was to:
Facilitate the creation/reuse of descriptive and administrative metadata across preservation and management systems.
But, for additional context, as part of the overall workflow, we also wanted to:
- streamline the ingest and deposit of content in a preservation repository;
- find solutions that met the Bentley’s local needs, but which were also flexible and scalable for other institutions; modular, so that institutions may adopt some, none, or all of the development features; and based upon open standards so that other tools and/or repository platforms could be integrated; and
- share all code and documentation with the archives and digital preservation communities.
And, just to give you a sense of why we were interested in this, let me show you where we were coming from…

We had been doing digital processing with a bunch of localized, disparate, silos of data and metadata that didn’t really work together at all.
So for example, here’s how we tracked accessions in a FileMaker Pro database (affectionately called BEAL).

We also used to do arrangement and description work of both physical and digital archives in Microsoft Word documents, generating Encoded Archival Description (EAD) using macros applied to various Microsoft Word styles.

And, we did digital processing with the AutomatedProcessor (AutoPro), a homegrown digital preservation tool written in Windows shell scripts.
Why Integrate ArchivesSpace and Archivematica?
While the use of FileMaker Pro, Microsoft Word, and AutoPro for digital processing lowered technical barriers and introduced efficiencies into the our digital processing initiatives, there were numerous shortcomings.
- The use of a custom FileMaker Pro database, for example, limited our ability to take advantage of the affordances of more widely-used systems (e.g., Archon and Archivists’ Toolkit and later ArchivesSpace), such as the ability to integrate with other tools.
- Using Microsoft Word to generate EADs was certainly easier than hand-encoding XML, but training processors in Microsoft Word styles and macros made the process very localised and more complicated than, say, ArchivesSpace, for entering descriptive information.
- AutoPro had limited error handling, a poor user interface and various support issues, and was never really intended to be a long-term solution
- In general, there was also a lack of well-defined system(s) of record. This meant lots of duplicate/redundant metadata entry in various platforms, and also meant we had a really hard time managing this metadata over time.
- None of these tools, I’ll add, really helped us work at scale. At all.
Meanwhile, ArchivesSpace and Archivematica had emerged as two of the most exciting open source platforms for working with digital archives. We were adopting ArchivesSpace to be our system of record for descriptive and administrative metadata, and had begun a gradual migration of metadata from disparate systems into ArchivesSpace. We were also adopting Archivematica to be our system of record for born-digital processing and AIP creation, and had begun a gradual migration of our digital backlog into Archivematica.
Best of all…
Both systems (DSpace too!) play nicely with others!
…that is, both use common metadata standards, have APIs, are open-source (although that’s not necessarily a prerequisite for systems integration, but it helps), etc.
Sponsoring New Features in Archivematica
And so, for this grant, we sponsored some development in Archivematica, essentially paying Artefactual to develop a new “Appraisal and Arrangement” tab in Archivematica. In addition to being the spot where this ArchivesSpace-Archivematica integration would happen, this introduced functionality to appraise and review digital content from within Archivematica. (I’m not going to talk about this much but feel free to ask any questions…)
As it pertains to this webinar, however, it integrated Archivematica and ArchivesSpace via the introduction of an ArchivesSpace ‘pane’ within the Appraisal and Arrangement tab. This feature utilizes the ArchivesSpace API to:
- display resource records in a tree view depicting the intellectual hierarchy of archival objects in ArchivesSpace;
- create and edit descriptive metadata for new or existing archival objects; authored in Archivematica and written ArchivesSpace; and
- permit archivists to drag and drop digital content onto archival description to create ArchivesSpace digital object records.
After launching the ingest of Submission Information Packages (SIPs) in Archivematica, a related integration of Archivematica and DSpace automatically uploads a fully ingested AIP and associated descriptive metadata as a unique item in DSpace, the persistent URL of that item (its “handle”) will in turn be written back to ArchivesSpace so that it may serve as a link to either the digital content in ASpace or when archival description is exported to an EAD finding aid.
For an overview of the functionality of Archivematica’s Appraisal and Arrangement Tab, including the appraisal of digital content within the Appraisal and Arrangement Tab, the arrangement of content to corresponding ArchivesSpace Resource records, and the deposit of content to a DSpace collection, see the following video in the Bentley Digital Media Library: ArchivesSpace-Archivematica-DSpace Workflow Integration Part 2: Appraisal, Arrangement to ArchivesSpace and Deposit to DSpace.
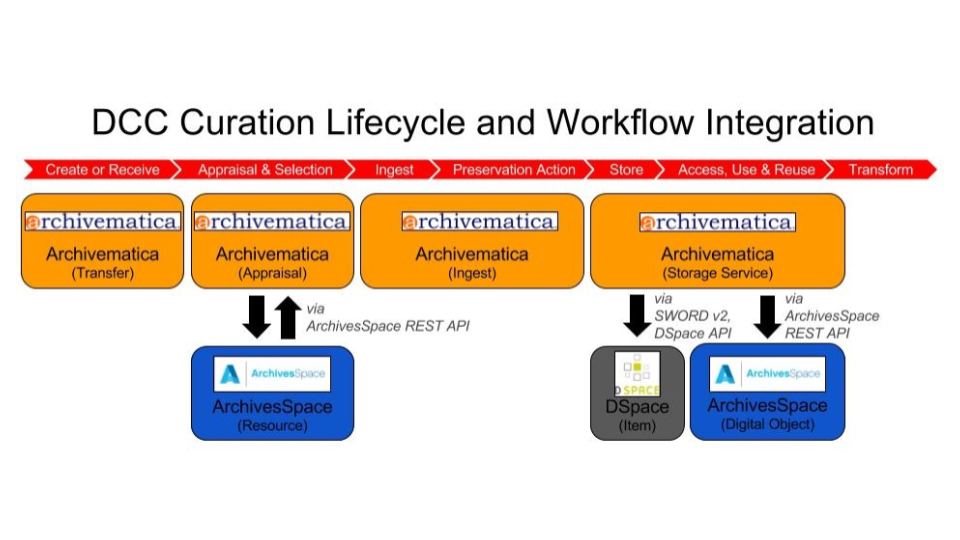
This systems integration, when mapped to a digital preservation workflow like the Digital Curation Centre Curation Lifecycle model, looks something like this. As you can maybe see, Archivematica’s the one doing the driving, data is flowing both bidirectionally and unidirectionally between systems at various stages of the workflow, and Archivematica is using various integration methodologies like the ArchivesSpace API to integrate with ArchivesSpace (as well as SWORD v2 and the DSpace API to integrate with DSpace, even though I didn’t really touch on those).
How well has this systems integration aged?
So, this was four years ago. You might be asking, how well has this systems integration aged?
Pretty well, actually! We still use it, to this day, just this morning, in fact! It has survived upgrades to both ArchivesSpace (started with 2.2 and are now on 2.5x), and Archivematica (1.6 to 1.9), as well as the latter’s migration to a new server.
I will stay that we use the particular workflow I outlined here less and less. It works really well for relatively small, heterogenous transfers, but that doesn’t exactly match the kind of accessions or transfers we usually get, which, more often, are small and homogenous or, regardless of whether their homogeneous or heterogeneous, are definitely trending on the bigger and bigger side (whether you measure that by number of files or size). As I showed earlier, we also have some more specialized platforms for digitized images and streaming audiovisual material, and this particular workflow obviously connects to DSpace but not to them.
That said, we do use this strategy of integration, and in particular integrations with systems, like ArchivesSpace and Archivematica and various other repository systems, that are designed to play nicely with others, more and more.
Lessons Learned
Which leads me to lessons learned. We’ve definitely drank the Kool-Aid and think systems integration is where it’s at. Side note: It turns out the integration of people is as challenging–if not more challenging–as the integration of systems (the proxies for those people), which is why I mentioned all of those stakeholders at the beginning.
Looking back, I think we’d now say that more important than any particular workflow is:
- just simply having systems that are designed to play nicely with others, without being super prescriptive about workflow (…it occured to me that even within Archivematica, this is the case. There’s one place to configure ArchivesSpace integration, and one-ish set of scripts that interacts with ArchivesSpace, namely
agent-archives, even though it enables at least two different workflows, the one I just showed and the one Bonnie is about to show…); and - beyond that, the technical and project management upskilling we did as as a team while implementing, migrating to, and integration ArchivesSpace and Archivematica was also really important. We learned a lot about how to make our tools work for us (and not the other way around).
As some evidence of that, here are a couple of GitHub repositories with code we’ve developed on our own based off of these integrations and the workflow they support:
AIP Repackagingscripts to support repackaging and depositing Archivematica AIPs to DSpace (essentially these help us to replicate the integration part of what I just showed without locking us in to a particular workflow);DAPPr, a Python-based API wrapper for DSpace that, again, allows us to get data and metadata into and out of DSpace in a programmatic way without being forced to use a particular workflow; and- lots of other ArchivesSpace repositories for plug-ins…
All of this results in the fact that…
We are now much more flexible in how we approach digital processing!
We now much prefer to sit down with a digital processing problem, think about what we want the end product to look like and all the different ways we might get there, see what patterns emerge, and go from there.
Categories: talks